Coroutines in C++ provide a way to suspend a function and resume it later.
They are not the same as threads. A thread is an operating-system execution context. A coroutine is a language-level mechanism that allows execution to be suspended without blocking the whole thread.
This makes coroutines useful for two major cases:
- lazy generation of values,
- asynchronous code that would otherwise require callbacks.
However, C++20 gives us mostly the coroutine machinery: language keywords, compiler-generated state machines, coroutine frames, promises, and handles.
It does not give us a complete async runtime.
There is no standard task, event loop, scheduler, or thread pool in C++20. To make coroutines practical, you either use a standard facility such as std::generator in C++23, implement your own coroutine types, or use a third-party library.
In this article, we will look at what coroutines are, where std::generator helps, and how a library such as libcoro can make coroutine-based asynchronous code usable in real projects.
What Coroutines Are
An ordinary function has a simple execution model:
- it receives arguments,
- executes instructions,
- returns a result,
- and its local state disappears when the function returns.
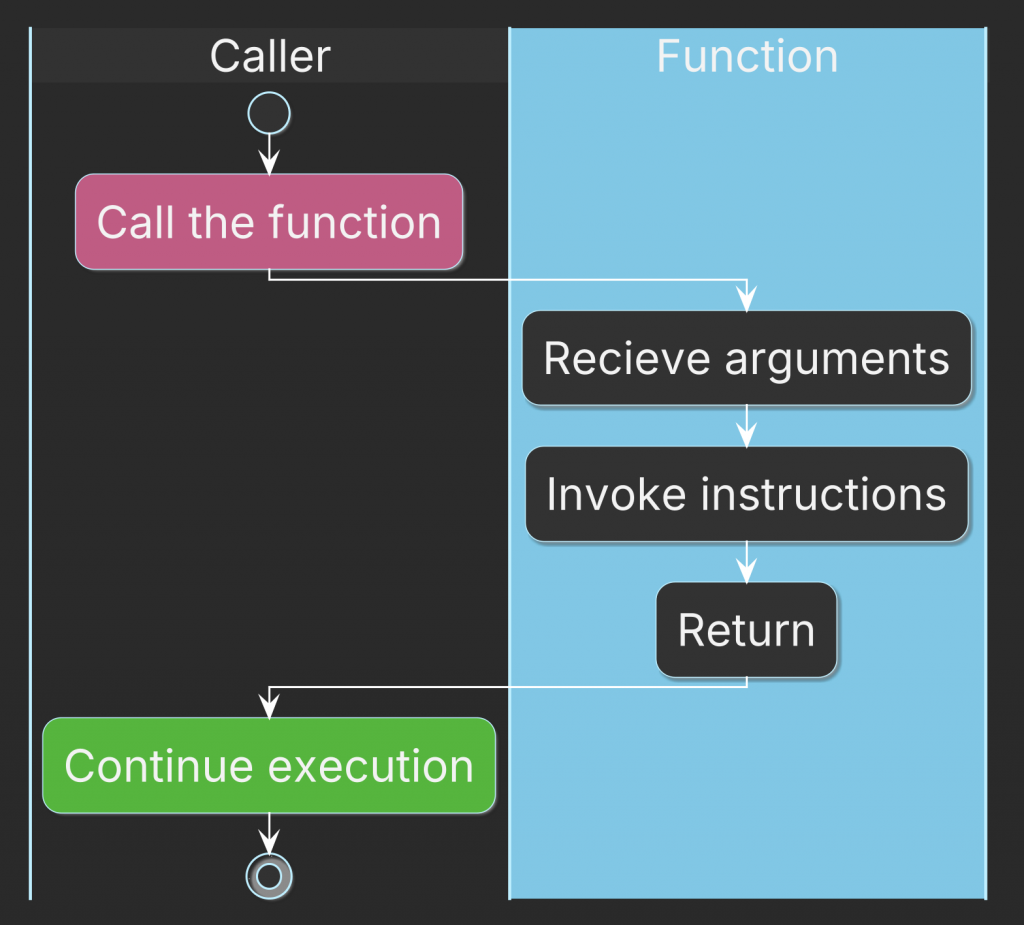
A coroutine is different.
A coroutine can suspend its execution and later continue from the same point.
That means its local variables and execution state must survive suspension. The compiler transforms a coroutine into a state machine and stores the required state in a coroutine frame.
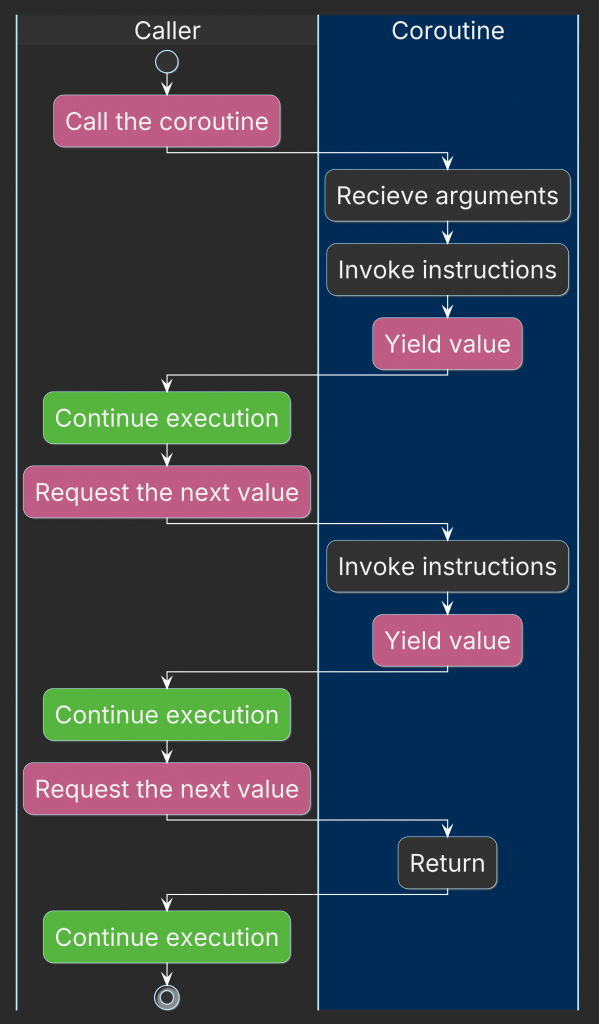
A function becomes a coroutine if it uses at least one of these keywords:
co_yield— produce a value and suspend,co_await— suspend until an awaitable operation is ready,co_return— complete the coroutine and return a final result.
Several objects are involved:
- the coroutine frame stores the coroutine state,
- the promise object customizes how values, suspension, exceptions, and completion are handled,
- the coroutine handle can be used to resume, destroy, or inspect the coroutine,
- the return object is what the caller receives.
This design is powerful, but low-level.
That is why raw C++20 coroutines are rarely used directly in application code. In practice, developers usually work with higher-level abstractions: generators, tasks, schedulers, and async libraries.
Generator Example: SAX-like Parser
One of the simplest practical coroutine abstractions is std::generator.
It is useful when a function needs to produce a sequence of values lazily. Instead of returning the whole collection at once, the function can produce one value, suspend, and continue only when the caller requests the next one.
This is especially useful for parser-like code.
For example, SAX-style parsers usually report events through callbacks. With a generator, the parser can return the next event as a value and suspend until the caller asks for another one.
Here is a simplified XML event parser implemented with std::generator:
#include <generator>
#include <cctype>
#include <iostream>
#include <stdexcept>
#include <string>
#include <string_view>
struct XmlEvent {
enum class Type {
StartElement,
EndElement,
Text
};
Type type;
std::string value;
};
static std::string_view trim(std::string_view text)
{
while (!text.empty() &&
std::isspace(static_cast<unsigned char>(text.front()))) {
text.remove_prefix(1);
}
while (!text.empty() &&
std::isspace(static_cast<unsigned char>(text.back()))) {
text.remove_suffix(1);
}
return text;
}
std::generator<XmlEvent> parse_xml(std::string_view xml)
{
while (!xml.empty()) {
auto open_pos = xml.find('<');
if (open_pos == std::string_view::npos) {
auto text = trim(xml);
if (!text.empty()) {
co_yield XmlEvent{
.type = XmlEvent::Type::Text,
.value = std::string{text}
};
}
co_return;
}
if (open_pos > 0) {
auto text = xml.substr(0, open_pos);
co_yield XmlEvent{
.type = XmlEvent::Type::Text,
.value = std::string{text}
};
xml.remove_prefix(open_pos);
continue;
}
auto close_pos = xml.find('>');
if (close_pos == std::string_view::npos) {
throw std::runtime_error("unterminated tag");
}
auto tag = xml.substr(1, close_pos - 1);
tag = trim(tag);
xml.remove_prefix(close_pos + 1);
if (tag.empty()) {
throw std::runtime_error("empty tag");
}
if (tag.front() == '/') {
tag.remove_prefix(1);
tag = trim(tag);
co_yield XmlEvent{
.type = XmlEvent::Type::EndElement,
.value = std::string{tag}
};
} else {
co_yield XmlEvent{
.type = XmlEvent::Type::StartElement,
.value = std::string{tag}
};
}
}
}
`
A generator uses co_yield to provide the next value. Its interface is compatible with ranges. In other words, a std::generator can be used in places where an input range is expected: range-based for loops, range algorithms, and other range-based code.
Here is how to use it:
int main()
{
std::string xml =
R"(<book><title>Hello coroutines</title><author>Someone</author></book>)";
for (const auto& event : parse_xml(xml)) {
switch (event.type) {
case XmlEvent::Type::StartElement:
std::cout << "START: " << event.value << '\n';
break;
case XmlEvent::Type::EndElement:
std::cout << "END: " << event.value << '\n';
break;
case XmlEvent::Type::Text:
std::cout << "TEXT: [" << event.value << "]\n";
break;
}
}
}
For simplicity, this parser does not handle attributes, comments, CDATA, namespaces, malformed XML edge cases, or self-closing tags properly.
But it demonstrates the main idea.
A generator does not need a separate class with fields to store intermediate parsing state. The state lives in the coroutine frame and is represented by ordinary local variables inside the function.
So instead of writing a stateful parser object manually, we can express the parser as a function that yields events.
However, std::generator covers only one practical coroutine use case: lazy synchronous value generation.
It does not provide an async runtime. It does not give us a standard task, scheduler, event loop, or thread pool.
That is where third-party libraries come in.
Want more practical Modern C++ explanations like this?
I write a monthly newsletter, From complexity to essence in C++, where I explain Modern C++, CMake, testing, and real-world engineering trade-offs with clear examples.
Subscribe here: From complexity to essence in C++
Using libcoro: task, scheduler, thread_pool
Coroutines can simplify asynchronous code by making it look closer to synchronous code.
Instead of passing callbacks through several layers, you can write code that waits at suspension points with co_await.
However, this requires library support.
Someone still needs to:
- define coroutine return types,
- resume suspended coroutines,
- schedule work,
- integrate I/O events,
- and decide where the coroutine continues execution.
A coroutine does not make blocking operations safe by itself.
Coroutines are cooperative. A coroutine runs until it reaches a suspension point. If it performs a blocking operation before suspension, the whole thread is blocked.
That is why blocking calls are dangerous on scheduler or event-loop threads. Blocking file I/O, blocking network calls, or waiting on a regular mutex can prevent other coroutines from making progress.
libcoro provides higher-level coroutine abstractions for this kind of code.
It defines useful coroutine types such as:
coro::task— a coroutine return type for asynchronous operations,coro::generator— a coroutine type for producing more than one value.
More importantly, it provides ways to run coroutines on different execution contexts:
coro::thread_pool— a fixed-size thread pool for running coroutine work,coro::scheduler— an I/O scheduler / event processing abstraction.
The main difference is that coro::scheduler behaves more like an event loop. It can process ready events, and it can also be integrated into an existing loop through process_events().
Let’s return to the SAX-like parser example.
The advantage of coroutines is not only that they can replace a stateful object with a function. Another important benefit is composition: parsing logic can be written as sequential code, while the caller decides where and how it is executed.
For example, parsing a large XML document can be scheduled on a worker thread via coro::thread_pool, while the main thread continues doing other work.
A simple coroutine extract_book can parse XML and extract information about a single book:
struct Book {
std::string title;
std::string author;
};
coro::task<Book> extract_book(std::string xml)
{
Book book;
std::string current_tag;
for (auto event : parse_xml(xml)) {
switch (event.type) {
case XmlEvent::Type::StartElement:
current_tag = event.value;
break;
case XmlEvent::Type::EndElement:
current_tag.clear();
break;
case XmlEvent::Type::Text:
if (current_tag == "title") {
book.title += event.value;
} else if (current_tag == "author") {
book.author += event.value;
}
break;
}
}
co_return book;
}
To make the overall example more relaistic let’s add a new corutine: print_book. It receives the result from extract_book and prints it. However, this corutine is executed in the main thread:
coro::task<void> print_book(
coro::task<Book> &&bookTask)
{
Book book = co_await bookTask;
std::cout << "title: " << book.title << '\n';
std::cout << "author: " << book.author << '\n';
co_return;
}
In main, we can:
- create a
coro::thread_pool, - schedule
extract_bookon it, - pass the task to the
print_book - wait until the coroutine completes.
int main()
{
auto pool = coro::thread_pool::make_unique(
coro::thread_pool::options{
.thread_count = 1
}
);
std::string xml = R"(
<book>
<title>Coroutines for the Tired</title>
<author>Some Human</author>
</book>
)";
auto bookTask = pool->schedule(extract_book(std::move(xml)));
coro::sync_wait(
print_book(std::move(bookTask)
);
std::cout << "title: " << book.title << '\n';
std::cout << "author: " << book.author << '\n';
return 0;
}
In a real application, the main thread should usually do useful work instead of immediately blocking with sync_wait. The main idea is that the main thread may invoke something else during print_book is suspended and waits until extract_book finishes.
That is where a scheduler becomes useful.
With a scheduler, the application can start asynchronous operations, process events, and resume coroutines when their awaited operations become ready.
The important point is this:
coroutines provide the suspension mechanism, but the runtime decides how suspended work is resumed.
C++20 gives us the mechanism. Libraries such as libcoro provide practical execution models on top of it.
Conclusion
Coroutines are one of the most powerful features added to modern C++.
But they are also easy to misunderstand.
C++20 coroutines are not a complete async framework. They do not automatically give you a task, event loop, scheduler, thread pool, or non-blocking I/O system.
What C++20 gives you is the low-level machinery:
- language keywords,
- compiler-generated state machines,
- coroutine frames,
- promise objects,
- coroutine handles.
To make coroutines practical, you need a higher-level abstraction.
For lazy synchronous sequences, std::generator provides a simple and useful model. It lets you express stateful iteration as a function that yields values one by one.
For asynchronous code, you need more infrastructure: tasks, schedulers, thread pools, and non-blocking operations. That is where libraries such as libcoro become useful.
The main value of coroutines is not that they magically make code faster.
The real value is that they make certain control flows easier to express:
- lazy generation without manual state machines,
- asynchronous code without deeply nested callbacks,
- sequential-looking logic over suspended execution.
But the same rule still applies:
a coroutine must not block the thread it runs on.
If a coroutine performs blocking I/O or waits on a blocking mutex, it can stop every other coroutine scheduled on the same thread from making progress.
So the practical mental model is simple:
C++20 gives you coroutine mechanics. Libraries and runtimes make them usable.
That is the difference between knowing what coroutines are and being able to apply them in a real C++ project.
Want to go deeper?
If you want to see how Modern C++, CMake, testing, tooling, and project structure fit together in a real application, I cover that in my book:
No More Helloworlds — Build a Real C++ App
It shows how to move beyond isolated examples and build a real C++ project with clean architecture, modern tooling, and practical engineering decisions.
Learn more: No More Helloworlds — Build a Real C++ App