Iterators are a fundamental concept in C++.
They serve as a bridge between STL containers and algorithms. For decades, most standard algorithms operated on a pair of iterators to traverse a sequence of values.
With the introduction of ranges in C++20 and their further refinement in C++23, the standard library gained a new abstraction that changes how data traversal is expressed in modern C++.
This article explores:
- which limitations naturally arise from the iterator-based model,
- how ranges reduce some of those problems,
- and where developers still need to be careful.
Where Iterator-Based APIs Become Error-Prone
The main limitation of iterator-based APIs is that an iterator points to a position in a sequence, but it does not represent the whole sequence.
In other words, when an algorithm receives a pair of iterators, it expects them to describe one valid range. Usually, that means both iterators must belong to the same container.
The compiler cannot generally enforce that.
For example, suppose we have two vectors in the same function scope and want to count the even elements in values:
#include <algorithm>
#include <vector>
std::vector<int> values = {1, 2, 3, 4, 5, 6, 7, 8, 2, 10};
std::vector<int> others = {20, 2, 40};
auto count = std::count_if(
values.begin(),
others.end(),
[](int x) { return x % 2 == 0; }
);
By mistake, std::count_if receives the begin iterator from values and the end iterator from others.
The code compiles because both iterators have compatible types. But the pair does not describe a valid range. The algorithm starts traversing values, while using the end iterator from others as the stopping point.
That violates the contract of the algorithm and leads to undefined behavior.
This is exactly the kind of mistake that ranges make harder to express. Instead of passing two independent iterators, a range-based algorithm can receive the sequence as a single object:
auto count = std::ranges::count_if(
values,
[](int x) { return x % 2 == 0; }
);
Now the algorithm gets the whole values range. There is no separate begin/end pair to accidentally mix with another container.
Another common issue is iterator invalidation.
You may face it simply by caching an iterator to a std::vector and then modifying the vector:
#include <algorithm>
#include <vector>
std::vector<int> values;
values.reserve(5);
values = {1, 2, 3, 4, 5};
auto first = values.begin();
values.push_back(6); // forces reallocation because size == capacity
auto count = std::count_if(
first,
values.end(),
[](int x) { return x % 2 == 0; }
);
In this example, first is obtained before the vector is modified.
When push_back needs more capacity, std::vector reallocates its internal storage. All previously obtained iterators become invalid, including first.
Using that invalidated iterator is undefined behavior.
Again, the compiler does not complain. The code may even appear to work during testing. But it relies on an iterator that no longer points into the valid storage of the vector.
Ranges do not magically remove all lifetime and invalidation problems. However, they reduce the need to manually pass and store iterator pairs. In many cases, that makes traversal code shorter, clearer, and less error-prone.
Ranges as a Safer Abstraction
Ranges in C++ are not just another nice-to-have feature. They change how we express traversal over sequences.
Instead of working with two independent iterators, which may or may not describe one valid sequence, ranges allow algorithms to operate on the sequence as a single object.
Iterators model positions.
Ranges model sequences.
The std::ranges::range concept requires that std::ranges::begin(r) and std::ranges::end(r) are valid expressions for an object r.
In the ranges model, begin() returns an iterator to the first element, while end() returns a sentinel that marks the end of the range. In many cases, that sentinel is an iterator too, but it does not have to be.
Iterators do not disappear. They are still used internally. The difference is that they are hidden behind a higher-level abstraction.
As a result, functions that operate on ranges can accept entire containers directly, without forcing the caller to manually extract and pass iterator pairs.
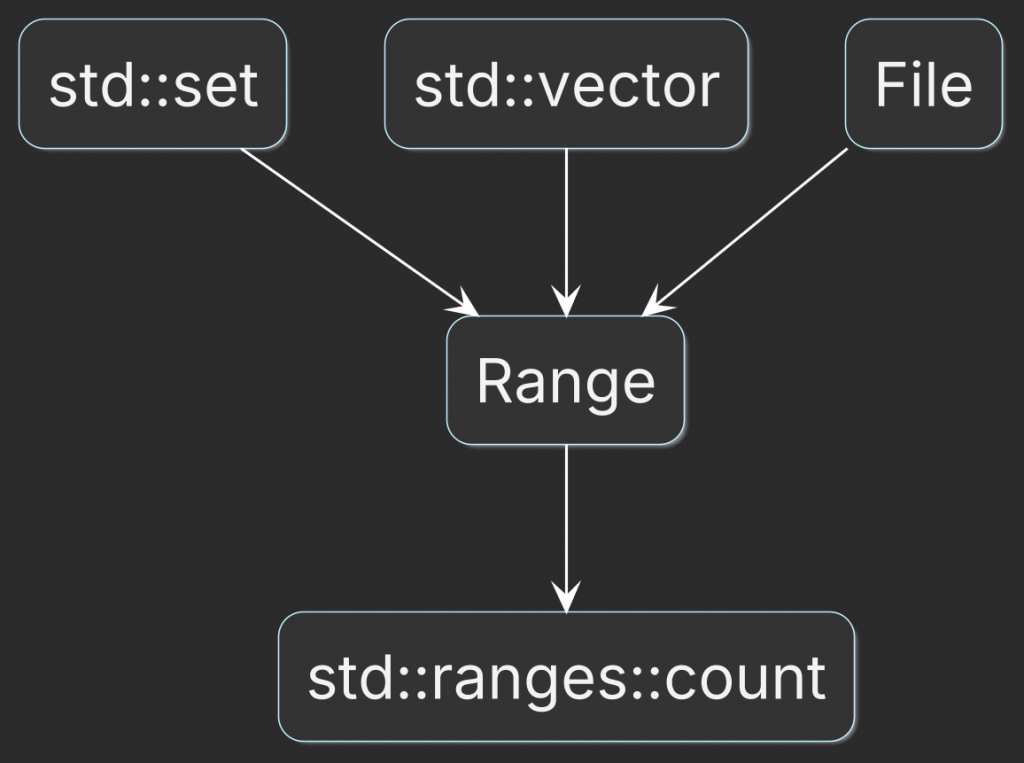
Adopting ranges required changes in the standard library itself. C++20 introduced range-based algorithms that accept a range instead of a pair of iterators.
This makes some iterator-related mistakes harder to write.
For example, with iterator-based algorithms, it is possible to accidentally pass the begin iterator from one container and the end iterator from another. With range-based algorithms, the sequence is passed as one argument.
For example, std::ranges::count_if performs the same task as std::count_if, but operates directly on the range:
#include <algorithm>
#include <vector>
std::vector<int> values = {1, 2, 3, 4, 2, 6, 7, 2, 9, 0};
auto count = std::ranges::count_if(
values,
[](int x) { return x % 2 == 0; }
);
Here, the algorithm receives the whole values range. There is no separate begin / end pair that can accidentally be mixed with another container.
Internally, iterators are still used. But the caller no longer needs to manage them directly, which makes the API clearer and less error-prone.
Ranges also help with some dangling iterator problems.
Some range algorithms return iterators. For example, std::ranges::find() returns an iterator when it is called with an lvalue range:
#include <algorithm>
#include <iostream>
#include <vector>
std::vector<int> values = {0, 1, 2, 3};
auto it = std::ranges::find(values, 1);
if (it != values.end()) {
std::cout << "found: " << *it << '\n';
}
In this case, values outlives the returned iterator, so using the iterator is safe.
But if a temporary container is passed to the algorithm, returning an iterator into that temporary would be dangerous. The container is destroyed at the end of the full expression, and the iterator would immediately dangle.
To prevent this, range algorithms return std::ranges::dangling for non-borrowed temporary ranges:
auto result = std::ranges::find(std::vector<int>{0, 1, 2, 3}, 1);
Here, result has type std::ranges::dangling, not an iterator.
The type std::ranges::dangling cannot be dereferenced or compared like an iterator. So code that tries to use it as if it were a valid iterator will not compile:
auto result = std::ranges::find(std::vector<int>{0, 1, 2, 3}, 1);
// Compilation error: std::ranges::dangling is not an iterator.
std::cout << *result << '\n';
This is an important improvement over traditional iterator-based APIs: some lifetime mistakes become visible at compile time.
However, ranges do not remove all lifetime problems. Many views are lightweight and non-owning. If a view refers to data whose lifetime has ended, the program can still be wrong.
So the more precise statement is:
ranges make traversal contracts more explicit, but they do not eliminate the need to reason about ownership and lifetime.
Iterators remain useful when traversal must start from an arbitrary position or when low-level control is required. But this flexibility comes with more responsibility.
Ranges preserve much of that flexibility while providing safer and more expressive tools for common traversal patterns.
The next subsection explains how views make such traversal composable without manually managing iterator pairs.
Want more practical Modern C++ breakdowns like this?
I write a monthly newsletter, From complexity to essence in C++, where I explain Modern C++, CMake, testing, and real-world engineering trade-offs with examples and clear mental models.
Subscribe here: From complexity to essence in C++
Views: Composable and Lazy Sequence Manipulation
Views are another important concept built on top of ranges.
A view is a lightweight range. Many views are non-owning and simply refer to the underlying data, although some views may own their data. In practice, views are designed to be cheap to move around and easy to compose.
What makes views especially powerful are view adapters.
A view adapter is a callable object or function that creates a new view from an existing range. For example, adapters can skip elements, take only part of a sequence, filter values, or transform elements.
Adapters can also be stacked on top of each other, forming a lazy processing pipeline.
No actual processing happens when the pipeline is created. The work is performed only when the resulting view is traversed by an algorithm or a loop.
View adapters replace many iterator-based patterns with a clearer alternative. Instead of manually storing begin and end iterators and carefully advancing them, traversal logic can be expressed declaratively:
#include <algorithm>
#include <iostream>
#include <ranges>
#include <vector>
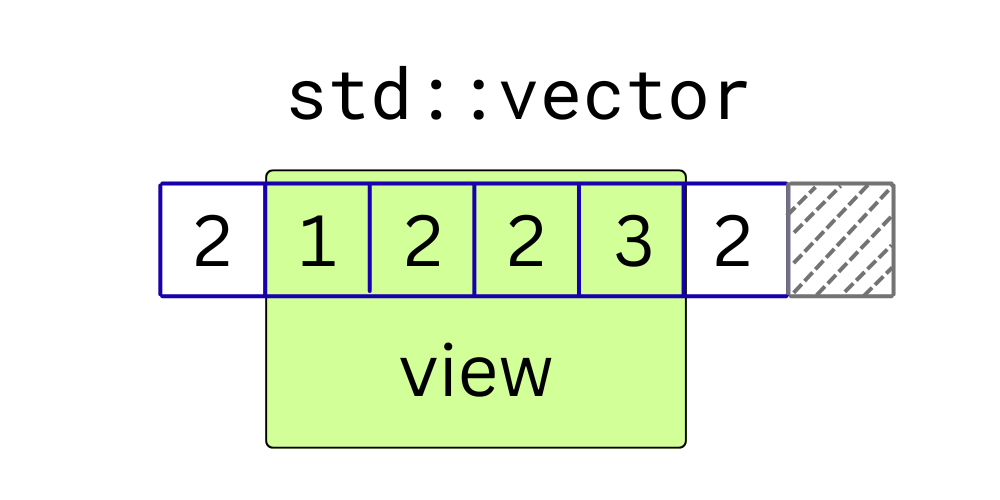
std::vector<int> values = {2, 1, 2, 2, 3, 2};
// Skip the first element and then take the next four.
auto count_2 = std::ranges::count(
values
| std::views::drop(1)
| std::views::take(4),
2
);
std::cout << "Found 2: " << count_2 << '\n';
This code does not manually advance iterators. The intent is visible directly in the pipeline:
- skip the first element,
- take the next four elements,
- count the number of
2s.
By encapsulating traversal logic, view adapters reduce the amount of manual iterator manipulation. That makes it harder to accidentally step past sequence boundaries or mix unrelated iterator pairs.
Views also enable expressive operations that previously required custom loops.
For example, filtering and transforming a sequence can be written as a single pipeline:
#include <algorithm>
#include <iostream>
#include <ranges>
#include <vector>
std::vector<int> values = {1, 2, 3, 4, 5, 6};
// Take only even numbers and multiply them by 10.
auto transformed =
values
| std::views::filter([](int v) { return v % 2 == 0; })
| std::views::transform([](int v) { return v * 10; });
for (int v : transformed) {
std::cout << v << '\n';
}
The pipeline itself does not create a new container. It describes how the data should be traversed.
The filtering and transformation are performed lazily: each element is filtered and transformed only when the view is actually iterated.
This laziness is one of the reasons views are efficient. They allow us to express complex traversal logic without allocating intermediate containers.
However, views do not remove the need to think about lifetime. Many views refer to existing data. If the underlying data does not outlive the view, the program can still be wrong.
So the main benefit is not that views make lifetime issues disappear. They make traversal code more explicit, more composable, and less dependent on manual iterator handling.
Conclusion
Iterators are still fundamental to C++. Ranges and views do not replace them — they provide a higher-level way to express traversal.
The main weakness of iterator-based APIs is that correctness depends on implicit contracts: both iterators must describe one valid range, must not be invalidated, and must refer to data that is still alive. The compiler usually cannot enforce those rules.
Ranges improve this by making the sequence itself part of the API. Algorithms can operate on a range directly, and views allow traversal logic to be composed declaratively without manually managing iterator pairs.
This makes code clearer, shorter, and less error-prone.
But ranges are not magic. Views are often lazy and non-owning, so lifetime still matters.
The real improvement is not that C++ became completely safe.
The improvement is that modern C++ gives us better abstractions for expressing traversal correctly.
Want to go deeper?
If you want to see how Modern C++, CMake, testing, and project structure fit together in a real application, I cover that in my book:
No More Helloworlds — Build a Real C++ App
It shows how to move beyond isolated examples and build a real C++ project with clean architecture, modern tooling, and practical engineering decisions.
Learn more:No More Helloworlds — Build a Real C++ App