Adding std::mutex to a codebase does not automatically make it thread-safe.
Used incorrectly, std::mutex can introduce hidden bugs, sporadic failures, and undefined behavior.
In this article, I’ll walk through the most important rules for using std::mutex safely in C++.
But before we get to those rules, it’s important to understand how std::mutex actually works.
So let’s start there.
How std::mutex works
std::mutex has two states:
- locked
- unlocked
Its member functions, std::mutex::lock() and std::mutex::unlock(), transition the mutex between those states.
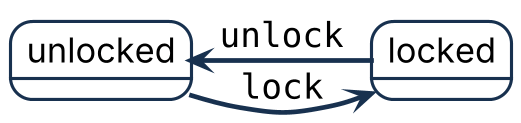
When the first thread locks a mutex, the mutex enters the locked state and that thread continues execution.
If another thread tries to lock the same mutex while it is already locked, that thread blocks until the mutex becomes available.
A call to std::mutex::unlock() releases the mutex and allows one waiting thread to continue.
Wrapping operations on shared state with std::mutex::lock() and std::mutex::unlock() prevents simultaneous access from multiple threads and protects the data from races.
For example, if an instance of BankAccounts is shared across threads, the following code shows how to safely add a new account:
struct Account {
std::string name;
int balance;
};
class BankAccounts{
public:
void createNew(std::string name, int balance) {
m_mutex.lock();
m_accounts.emplace_back(std::move(name), balance);
m_mutex.unlock();
}
private:
mutable std::mutex m_mutex;
std::vector<Account> m_accounts;
};
Rule #1: Always use RAII for locking
The code below might look acceptable in C, but in C++ it is fragile and unsafe:
class BankAccounts{
public:
void get(std::size_t i) {
Account account;
m_mutex.lock();
account = m_accounts.at(i);
m_mutex.unlock();
return account;
}
};
Here, BankAccounts::get() returns an account by index. The problem is that if m_accounts.at(i) throws an exception, the mutex is never unlocked. Any later attempt to lock the same mutex will block forever, resulting in a deadlock.
C++ solves this with the RAII pattern, and the simplest tool for that is std::lock_guard. It:
- takes a mutex in its constructor,
- locks it immediately,
- unlocks it in its destructor.
That means it doesn’t matter how the function exits — whether by returning normally or by throwing an exception. The destructor of std::lock_guard is still called, and the mutex is released safely.
The rewritten version is not only safer, but also shorter and easier to read:
class BankAccounts{
public:
void get(std::size_t i) {
auto guard = std::lock_guard{m_mutex};
return m_accounts.at(i);
}
};
std::lock_guard is the simplest mutex wrapper, and in most cases it is exactly what you need. Other options exist — such as std::unique_lock and std::scoped_lock — but they are better suited to more advanced cases, such as deferred locking, locking multiple mutexes, or working with shared/exclusive locking.
My rule of thumb is simple:
If all you need is safe lock/unlock around one mutex, use
std::lock_guard.
Rule #2: One shared state → one synchronization boundary
Using multiple mutexes in the same class to protect related data can easily lead to undefined behavior. If, by mistake, one mutex is used for writes and another is used for reads of the same shared state, the result is a data race.
For example, imagine that BankAccounts grows new logic and now stores two groups of accounts: ordinary accounts and premium accounts. The class now has another member, m_premiumAccounts, and a second mutex to protect it. At first glance, this seems reasonable: separate mutexes may allow more parallelism when the two groups are accessed independently:
class BankAccounts{
public:
void createNewPremium(std::string name, int balance) {
auto guard = std::lock_guard{m_premiumAccountsMutex};
m_premiumAccounts.emplace_back(std::move(name), balance);
}
private:
mutable std::mutex m_accountsMutex;
std::vector<Account> m_accounts;
mutable std::mutex m_premiumAccountsMutex;
std::vector<Account> m_premiumAccounts;
};
The real problem is that there is no explicit binding between a mutex and the shared state it is supposed to protect. Because of that, both the compiler and even a code reviewer can easily miss a bug where the wrong mutex is locked.
That is exactly what happens in the example where the total balance of premium accounts is calculated while the code locks m_accountsMutex instead of m_premiumAccountsMutex. Writes use m_premiumAccountsMutex, reads use m_accountsMutex, and the result is a data race with undefined behavior:
class BankAccounts{
public:
int sumPremium() const {
auto guard = std::lock_guard{m_accountsMutex};
return std::accumulate(
m_premiumAccounts.cbegin(), m_premiumAccounts.cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
private:
mutable std::mutex m_accountsMutex;
std::vector<Account> m_accounts;
mutable std::mutex m_premiumAccountsMutex;
std::vector<Account> m_premiumAccounts;
};
A better solution is one of these:
- use a single mutex for the whole
BankAccountsobject, or - move the protected state into a smaller class that owns both the data and its mutex, and then compose those smaller classes.
For example, you can introduce a SetBankAccounts class that owns one vector of accounts and one mutex:
struct Account {
std::string name;
int balance;
};
class SetBankAccounts{
public:
void createNew(std::string name, int balance) {
auto guard = std::lock_guard{m_mutex};
m_accounts.emplace_back(std::move(name), balance);
}
int sum() const {
auto guard = std::lock_guard{m_mutex};
return std::accumulate(
m_accounts.cbegin(), m_accounts.cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
private:
mutable std::mutex m_mutex;
std::vector<Account> m_accounts;
};
Then BankAccounts becomes a composition of two SetBankAccounts objects: one for ordinary accounts and one for premium accounts:
class BankAccounts{
public:
void createNewPremium(std::string name, int balance) {
m_premium.createNew(std::move(name), balance);
}
int sumPremium() const {
return m_premium.sum();
}
private:
SetBankAccounts m_accounts;
SetBankAccounts m_premium;
};
This design makes the mental model much simpler:
- synchronization happens at the
SetBankAccountslevel, BankAccountsitself no longer needs to manage multiple mutexes,- and because each state has exactly one synchronization boundary, it becomes much harder to lock the wrong mutex by accident.
My rule of thumb is simple:
One shared state should have one clear synchronization boundary.
If that boundary becomes hard to explain, the design is usually the real problem.
Rule #3: Avoid std::recursive_mutex — fix the design instead
A regular std::mutex does not allow the same thread to call lock() twice on the same mutex.
By contrast, std::recursive_mutex does.
At first glance, that may look convenient. But in practice, reaching for std::recursive_mutex is often a sign that something is wrong with the design.
A mutex is supposed to define a clear synchronization boundary for shared state.
A recursive mutex weakens that boundary: it becomes much less obvious where the critical section really begins and ends.
For example, imagine BankAccounts needs a new function that adds an account only if the total balance of all existing accounts is still below a given limit. A natural implementation is to reuse two existing methods: sum() and createNew().
class BankAccounts{
public:
void createNew(std::string name, int balance) {
auto guard = std::lock_guard{m_mutex};
m_accounts.emplace_back(std::move(name), balance);
}
int sum() const {
auto guard = std::lock_guard{m_mutex};
return std::accumulate(
m_accounts.cbegin(), m_accounts.cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
bool createNew(std::string name, int balance, int limit){
auto guard = std::lock_guard{m_mutex};
auto sum = sum();
if(sum >= limit){
return false;
}
createNew(std::move(name), balance);
return true;
}
private:
mutable std::recursive_mutex m_mutex;
std::vector<Account> m_accounts;
};
With a regular std::mutex, this code deadlocks: the outer function locks the mutex, then sum() tries to lock it again from the same thread.
To make this version work, you would need std::recursive_mutex instead. And yes, std::lock_guard works with std::recursive_mutex too.
But that only treats the symptom — not the cause.
A better solution is to separate responsibilities:
- put the business logic into a class that does not own a mutex;
- then wrap it in a thin synchronization layer that locks once at the API boundary and forwards the call.
For example, BankAccountsImpl can implement the actual operations without any mutex at all:
class BankAccountsImpl{
public:
void createNew(std::string name, int balance) {
m_accounts.emplace_back(std::move(name), balance);
}
int sum() const {
return std::accumulate(
m_accounts.cbegin(), m_accounts.cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
bool createNew(std::string name, int balance, int limit){
auto sum = sum();
if(sum >= limit){
return false;
}
createNew(std::move(name), balance);
return true;
}
private:
std::vector<Account> m_accounts;
};
Then BankAccounts becomes a simple wrapper that handles multithreaded synchronization and dispatches calls to BankAccountsImpl under one std::mutex:
class BankAccounts{
public:
void createNew(std::string name, int balance) {
auto guard = std::lock_guard{m_mutex};
m_impl.createNew(std::move(name), balance);
}
int sum() const {
auto guard = std::lock_guard{m_mutex};
return m_impl.sum();
}
bool createNew(std::string name, int balance, int limit){
auto guard = std::lock_guard{m_mutex};
return m_impl.createNew(std::move(name), balance, limit);
}
private:
mutable std::mutex m_mutex;
BankAccountsImpl m_impl;
};
This design makes responsibilities much clearer:
BankAccountsImplowns the business logicBankAccountsowns synchronization- the critical section begins at the start of each public method in
BankAccounts, and ends when that method returns
That gives you a simple and explicit synchronization boundary — without needing std::recursive_mutex.
My rule of thumb is simple:
If you think you need
std::recursive_mutex, first check whether the real problem is unclear class boundaries.
Conclusion
std::mutex is a powerful tool — but it is not a guarantee of thread safety by itself.
What really makes code safe is not the mutex alone, but the discipline behind it:
- use RAII instead of manual
lock()/unlock() - protect the same shared state with one clear synchronization boundary
- and if you feel tempted to reach for
std::recursive_mutex, first rethink the design
In practice, most mutex-related bugs are not caused by the primitive itself. They come from blurry boundaries, inconsistent locking, and code that grew faster than its concurrency model.
The good news is that these problems are fixable.
Once the boundaries are clear, thread-safe code becomes much easier to reason about.
If you enjoy practical breakdowns like this, I share one deep dive each month in my newsletter From complexity to essence in C++ — focused on Modern C++, CMake, and real-world engineering trade-o