In C++, shared data must be protected against simultaneous access from multiple threads; otherwise, the program exhibits undefined behavior.
For complex classes like std::vector, a common solution is to guard every read and write with a std::mutex.
However, when reads dominate and writes are rare, a mutex can become a scalability bottleneck: every read still has to take the lock, even if it only performs a long computation over the data.
In such “read-mostly” scenarios, a copy-on-write snapshot built on std::atomic<std::shared_ptr> can be a good fit. Readers share an immutable snapshot, while a writer creates and updates a new snapshot and then publishes it atomically. In this article, I’ll show you how to implement this pattern using std::atomic.
Why a Mutex Doesn’t Scale for Read-Mostly Workloads
Let’s consider a simple example: a container holding bank accounts, where each account is represented by an Account struct and stored inside the BankAccounts class.
The class provides two methods:
BankAccounts::create_new()— creates a new account.BankAccounts::sum()— calculates the sum of all account balances.
To prevent data races and corruption, both methods use a std::mutex to synchronize access to the shared container:
struct Account {
std::string name;
int balance;
};
class BankAccounts{
public:
int sum() const {
auto lock = std::lock_guard{m_mutex};
return std::accumulate(m_accounts.cbegin(), m_accounts.cend(), 0,
[](int res, const Account &acc){return res + acc.balance;});
}
void create_new(std::string name, int balance) {
auto lock = std::lock_guard{m_mutex};
m_accounts.emplace_back(std::move(name), balance);
}
private:
mutable std::mutex m_mutex;
std::vector<Account> m_accounts;
};
With this approach, all threads in the application share the same view of m_accounts. In other words, they read and modify the same underlying data, as shown in the diagram below.
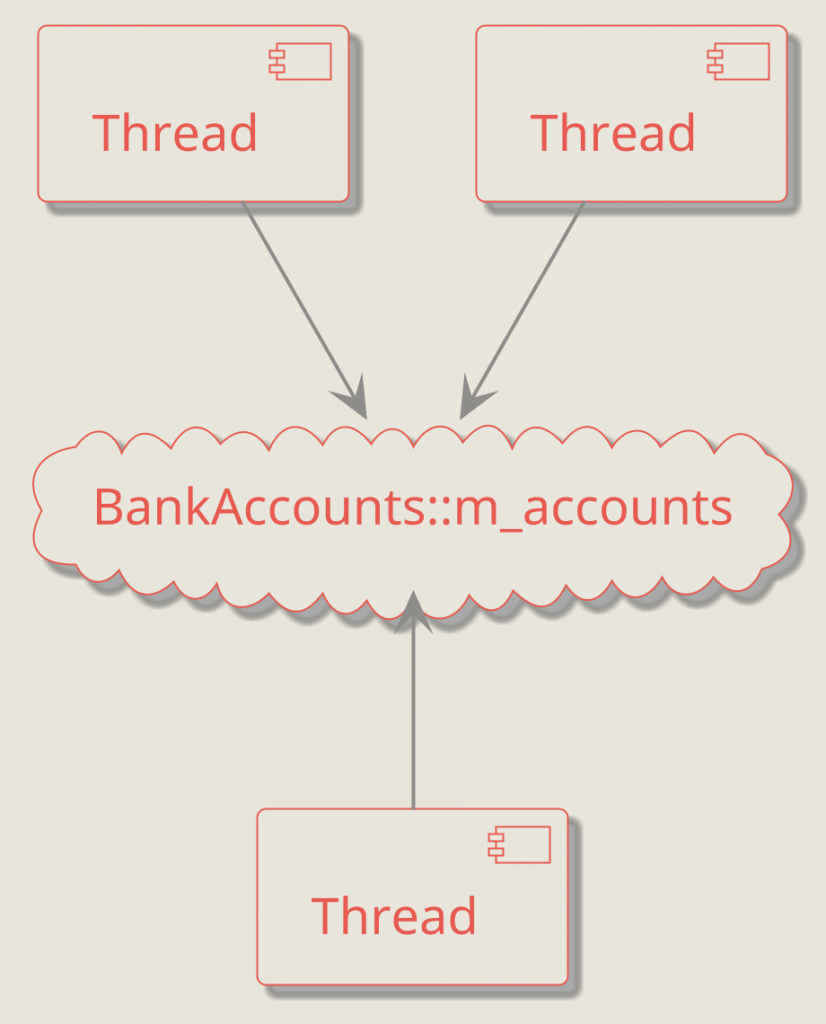
Now, imagine you need to generate not just one report, but several — each involving expensive computations. One option is to keep adding more methods to BankAccounts, each performing its calculation under the same mutex.
But if updates to the container are rare, this becomes inefficient: every report still has to lock the mutex, which prevents those computations from running in parallel.
An alternative is to use a read–write lock, or to provide a method that returns a copy of m_accounts:
class BankAccounts{
public:
std::vector<Account> get() const {
auto lock = std::lock_guard{m_mutex};
return m_accounts;
}
};
This allows report functions to be implemented outside the class. However, it introduces another trade-off: each report must copy the entire vector. If new accounts are added only occasionally, that repeated copying can waste significant CPU time and memory bandwidth.
Copy-on-Write Snapshots with atomic<shared_ptr>
A possible solution is to combine std::atomic with std::shared_ptr. In this design, the member m_accounts holds an atomic shared pointer to a std::vector. This approach requires at least C++20, which introduced support for atomics of std::shared_ptr.
The member declaration now looks like this:
class BankAccounts {
// other methods
private:
std::atomic<std::shared_ptr<const std::vector<Account>>> m_accounts;
};
Read operations
For read operations (such as BankAccounts::sum), only the shared pointer itself needs to be accessed atomically. The actual computation—such as summing balances—can then run without any further synchronization:
class BankAccounts {
public:
// Summing balances in all accounts
int sum() const {
// Obtain the pointer to the accounts
auto values = m_accounts.load(std::memory_order_acquire);
// Run the calculations
return std::accumulate(
values->cbegin(), values->cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
private:
std::atomic<std::shared_ptr<const std::vector<Account>>> m_accounts;
};
Here, std::atomic::load returns a copy of the std::shared_ptr. Even if multiple threads call BankAccounts::sum simultaneously, each thread receives its own copy of the shared pointer. All those shared pointers, however, point to the same underlying std::vector, as shown in the diagram below.
Thanks to the reference-counting mechanism of std::shared_ptr, the vector will be destroyed only after the last shared pointer copy goes out of scope.
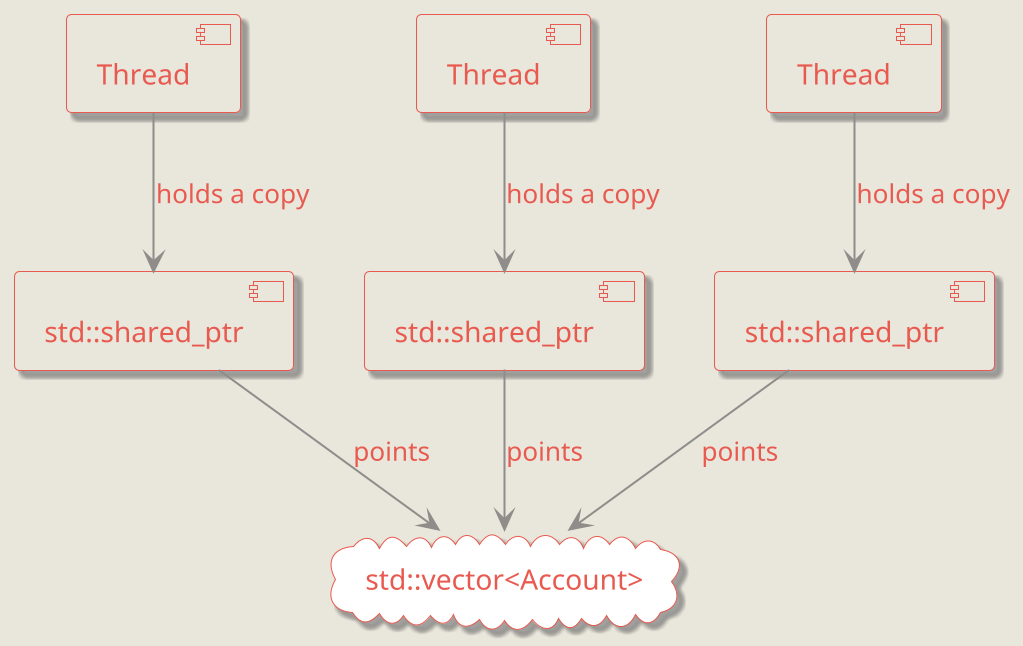
Thanks to the reference-counting mechanism of std::shared_ptr, the vector will be destroyed only after the last shared pointer copy goes out of scope.
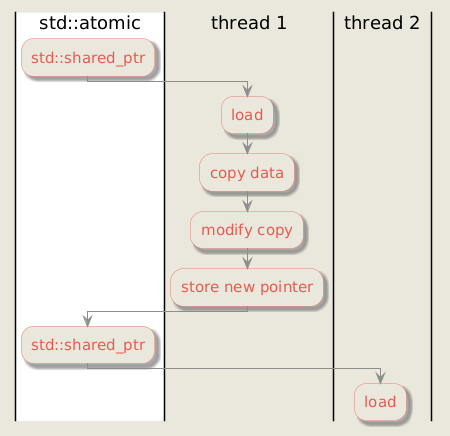
Load–modify–store operation
While reads are straightforward, writes are more complex. In this model, it is not safe to obtain a pointer to std::vector<Account> and modify the container in place. For this reason, m_accounts points to a const container.
Instead, an update works like this:
- make a deep copy of the current container,
- apply the modification to the copy,
- atomically update
m_accountsto point to the new container.
The overall process is illustrated in the diagram below.
This logic is implemented in BankAccounts::create_new:
class BankAccounts {
public:
// Other methods
// Add new account
void create_new(std::string name, int balance) {
auto old = m_accounts.load(std::memory_order_acquire);
bool isUpdated = false;
do {
// Construct the copy
auto new_values = std::make_shared<std::vector<Account>>(*old);
// Modify the value
new_values->emplace_back(name, balance);
// Update the pointer to accounts only if it wasn't modified
isUpdated = m_accounts.compare_exchange_strong(old, new_values, std::memory_order_release);
} while (!isUpdated);
}
private:
std::atomic<std::shared_ptr<const std::vector<Account>>> m_accounts;
};
Here, std::atomic::compare_exchange_strong is used to update m_accounts. If m_accounts holds a different pointer than old, it means another thread updated the container in the meantime, and the operation returns false. In that case, the loop retries using the latest data.
Without this retry loop, BankAccounts::create_new could accidentally overwrite changes made by other threads.
When BankAccounts::create_new finally returns, m_accounts points to the updated container, and all subsequent reads will observe the new pointer. At the same time, if some threads already hold a shared pointer to the old container, that pointer remains valid and safe to use for reporting, as shown in the diagram below.
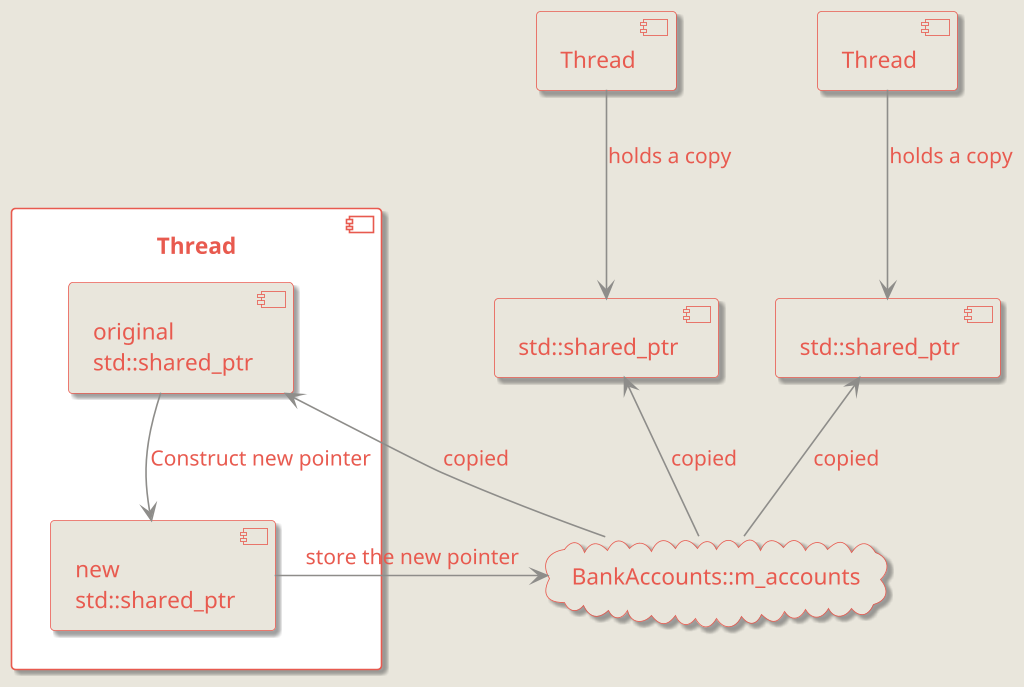
If some threads still hold shared_ptrs to the old data while m_accounts is updated to point to a new container, the old vector remains alive until the last shared_ptr is released. At that point, it is destroyed automatically.
When NOT to Use Copy-on-Write
A copy-on-write approach has several hard limitations that can make it impractical—or simply less efficient than a mutex-based solution:
- Frequent writes
The algorithm copies the entire container first and only then applies the modification. If the write rate is high, performance can degrade significantly due to repeated construction and destruction of large containers. - Heavy objects stored in the container
Copying “fat” objects is expensive. If most updates touch only a small part of each object, paying the cost of copying the whole object on every write may not be justified. In this case, a mutex (or another synchronization strategy) can be a better fit. - Complex invariants / non-trivial copy semantics
Some types are non-copyable, or support only shallow copying. For example, if an object contains astd::shared_ptr, copying the object may simply copy the pointer instead of performing a deep copy of the referenced data. That can make concurrent modifications harder and more error-prone.
Before choosing an approach, my advice is simple:
Measure on your target platform, and base the decision on real numbers—not guesses.
Reference Implementation
To ensure m_accounts is always properly initialized, we add two constructors:
- one that creates an empty container;
- one that builds the container from an existing
std::vector<Account>.
With this change, the class looks like this:
class BankAccounts {
public:
// Construct the container from existing vector
explicit BankAccounts(std::vector<Account> values)
: m_accounts(std::make_shared<std::vector<Account>>(std::move(values))) {}
// Construct an empty container
BankAccounts() : m_accounts(std::make_shared<std::vector<Account>>()) {}
};
In this way the overall class has the following view:
class BankAccounts {
public:
// Construct the container from existing vector
explicit BankAccounts(std::vector<Account> values)
: m_accounts(std::make_shared<std::vector<Account>>(std::move(values))) {}
// Construct an empty container
BankAccounts() : m_accounts(std::make_shared<std::vector<Account>>()) {}
public:
// Return a pointer to the data
std::shared_ptr<const std::vector<Account>> get() const {
return m_accounts.load();
}
// Summing balances in all accounts
int sum() const {
// Obtain the pointer to the accounts
auto values = m_accounts.load(std::memory_order_acquire);
// Run the calculations
return std::accumulate(
values->cbegin(), values->cend(), 0,
[](int res, const Account &acc) { return res + acc.balance; });
}
// Add new account
void create_new(std::string name, int balance) {
auto old = m_accounts.load(std::memory_order_acquire);
bool isUpdated = false;
do {
// Construct the copy
auto new_values = std::make_shared<std::vector<Account>>(*old);
// Modify the value
new_values->emplace_back(name, balance);
// Update the pointer to accounts only if it wasn't modified
isUpdated = m_accounts.compare_exchange_strong(old, new_values,
std::memory_order_release);
} while (!isUpdated);
}
private:
std::atomic<std::shared_ptr<const std::vector<Account>>> m_accounts;
};
With this design:
- the read path (
sum) requires no locks—just copying ashared_ptr; - the write path (
create_new) performs a copy-on-write update via atomic pointer replacement; m_accountsis always initialized (nevernullptr).
Performance Notes and Trade-offs
Strictly speaking, synchronization in BankAccounts isn’t truly lock-free: std::atomic<std::shared_ptr<...>> may (and often does) rely on internal locks to manage reference counting. However, the BankAccounts implementation itself uses no explicit locks, so from the API user’s perspective the read path is non-blocking and scales well under contention.
The copy-on-write approach enables concurrent reads of the underlying std::vector. Once a thread obtains a std::shared_ptr<const std::vector<Account>>, it can iterate over the snapshot without any additional synchronization (such as mutexes).
Writers can also safely publish an updated snapshot by atomically replacing the std::shared_ptr—without waiting for readers to finish. Existing readers continue working with the old snapshot, which remains alive until the last shared_ptr to it is released.
Rule of Thumb
Use copy-on-write snapshots when reads are frequent, writes are rare, and readers can work on immutable data.
Avoid it when writes are frequent or the data structure is expensive to copy.
Measure on your target platform.
In my monthly newsletter From complexity to essence in C++, I publish deep dives on Modern C++, concurrency patterns, and CMake — with minimal examples and practical rules of thumb:
https://sqglobe.com/from-complexity-to-essence-in-c/